Wie im Artikel zu Googles Crawling- und Indexierungsprozess dargestellt, können nur bekannte Dokumente gecrawlt und (unter Umständen) auch von Google indexiert werden. Einen Einblick darüber, wie es um die Indexierung einer Website insgesamt und einzelnen Websites steht, bietet der Bericht zur Seitenindexierung, oder auch kurz Indexierungsbericht, in der Google Search Console.
Im Juni 2022 hat Google den Bericht überarbeitet (siehe die Ankündigung im Google-Blog) und gruppiert seitdem die Daten in “Indexiert” und “Nicht-Indexiert”.

Inhaltsverzeichnis
Das Wichtigste zum Indexierungsbericht in der Übersicht:
- Google informiert über die Anzahl der (nicht) indexierten Seiten des Webauftritts
- Gründe für eine Nicht-Indexierung können durch Google oder die Website verursacht sein
- Bis zu 1.000 Beispiel-Adressen sind in den jeweiligen Fehlergruppen zu finden
- Eine Filterung des Berichts ist nach in der Search Console eingereichten XML-Sitemaps möglich
So arbeitest du mit dem Indexierungsbericht
Vorneweg: Der Indexierungsbericht bietet dir erstmal nur nummerische Zahlen. Du kannst also sehen, wie viele Adressen Google für deine Website kennt und wie viele davon (nicht) indexiert sind. Während die indexierten Seiten den Crawling- und Indexierungsprozess erfolgreich durchlaufen haben, gibt es für die Nicht-Indexierung unterschiedliche Gruppen. Diese kannst du im Beitrag zu Problemen mit der Google Indexierung nachlesen.
Zunächst einmal kannst du auswählen, ob du den Bericht nach „Alle bekannten Seiten“, oder nach „Alle eingereichten Seiten“ analysieren möchtest. Dazu steht dir oben links die Auswahl im Drop-Down zur Verfügung.
Was bedeutet „Alle bekannten Seiten“?
Wenn du dir den Indexierungsbericht unter „Alle bekannte Seiten“ anschaust, dann siehst du alle Google bekannten Adressen, ganz gleich, wo Google diese Adressen gefunden hat. Das ist quasi das „Gesamtbild“ deiner Website in den Augen von Google.
Was bedeutet „Alle eingereichten Seiten“?
Unter eingereichten Seiten sind Adressen zu verstehen, die über XML-Sitemaps (gerade) an Google gesendet wurden. Dazu reicht es nicht, die Sitemaps (nur) in der robots.txt-Datei zu referenzieren. Trage diese stattdessen über den separaten Sitemaps-Bericht in der Google Search Console manuell ein. Wenn du mehrere Sitemaps verwendest, dann solltest du dir einmalig die Arbeit machen und alle Sitemaps separat einreichen.

Was bedeutet „Nur nicht eingereichte Seiten“?
Google bietet auch noch eine dritte Ansicht an: Die „nicht eingereichten Seiten“. In diese Gruppe fallen alle Adressen, die (aktuell) nicht in eingereichten XML-Sitemaps enthalten sind. Diese kennt Google folglich durch andere Quellen wie vor allem interne und externe Verlinkungen.
Eine einzelne Sitemap im Bericht zur Seitenindexierung auswerten
Google bietet aber nicht nur die Betrachtung des Indexierungsberichts nach „alle eingereichten Seiten“ an, sondern zugleich für jede einzelne eingereichte Sitemap. Diese Ansicht kann entweder über das Drop-Down oben links, oder über die drei gestapelten Punkte hinter einer Sitemap im gleichnamigen Bericht aufgerufen werden.
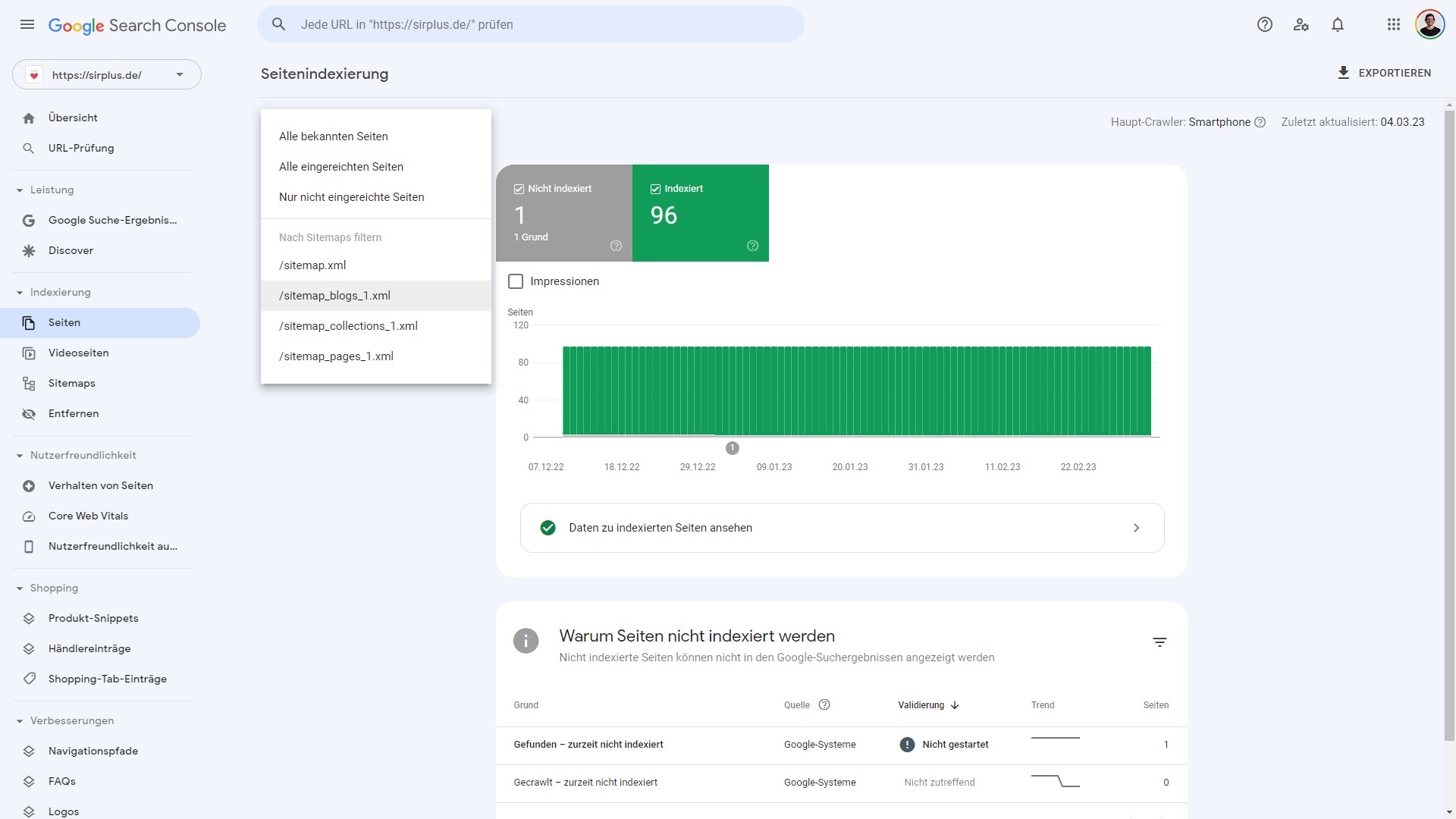
Welche Seiten sind (nicht) bei Google indexiert?
Auf der obersten Ebene unterteilt Google den Bericht in indexiert und „Warum Seiten nicht indexiert wurden“.
- Indexiert: Diese Adressen hat Google in den Google-Index aufgenommen
- Warum Seiten nicht indexiert sind: Hier befinden sich in verschiedene Gruppen sortiert die einzelnen Seiten, die Google (bisher) nicht indexiert hat
Mit dem Indexierungsbericht kannst du nachvollziehen, welche Seiten (nicht) von Google indexiert wurden. Dazu musst du eine einzelne Gruppierung aufrufen, denn dort sind die bis zu 1.000 Beispielseiten der jeweiligen Gruppe zu finden. So kannst du dir beispielsweise Adressen anzeigen lassen, die aufgrund einer Weiterleitung nicht indexiert („Seite mit Weiterleitung„) sind.
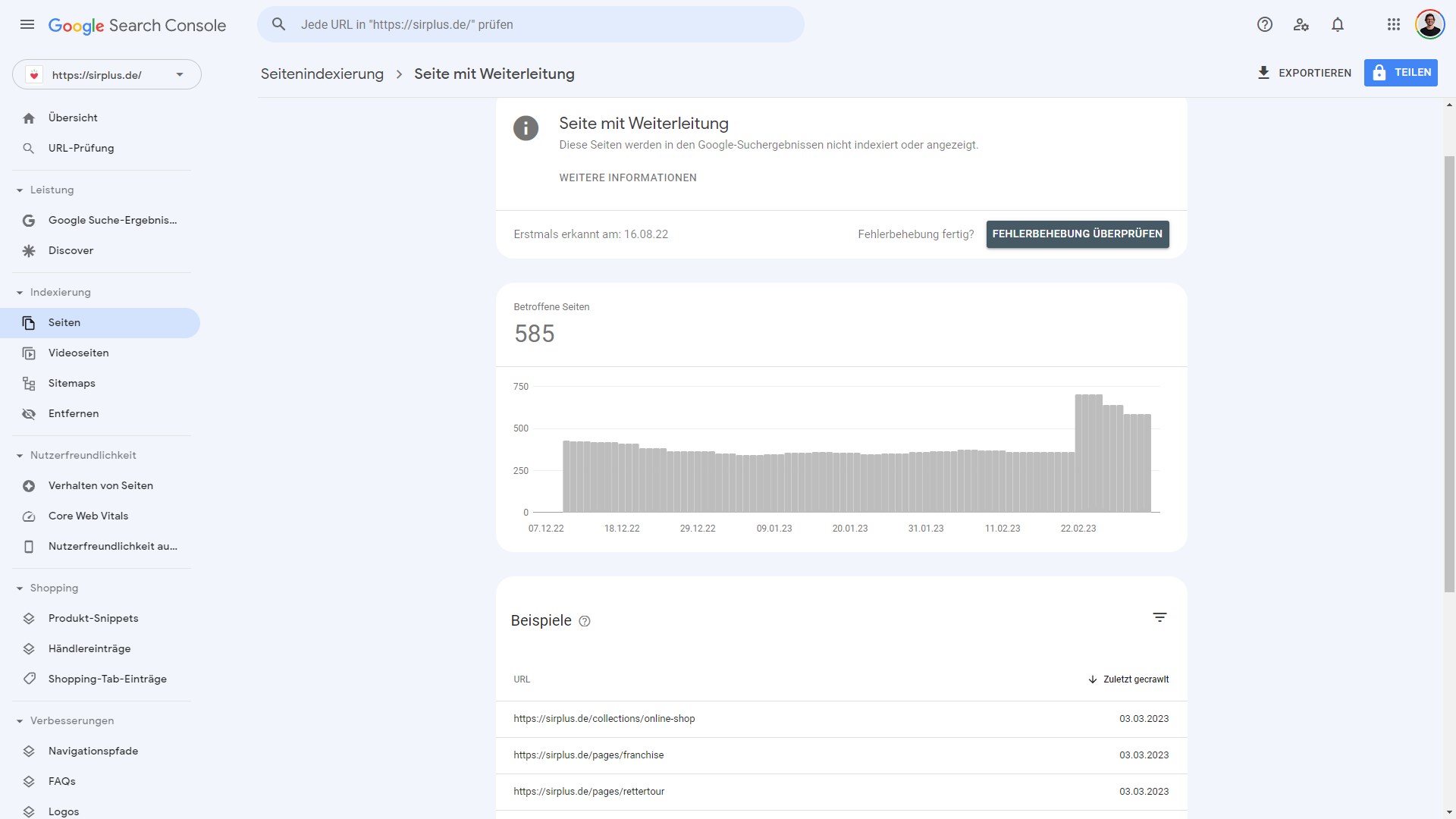
Doch nochmals zurück zur Übersichtseite. Hier ist verzeichnet, welche Quelle für eine Nicht-Indexierung gesorgt hat. Liegt der Grund auf der Website, oder innerhalb der Google-Systeme?
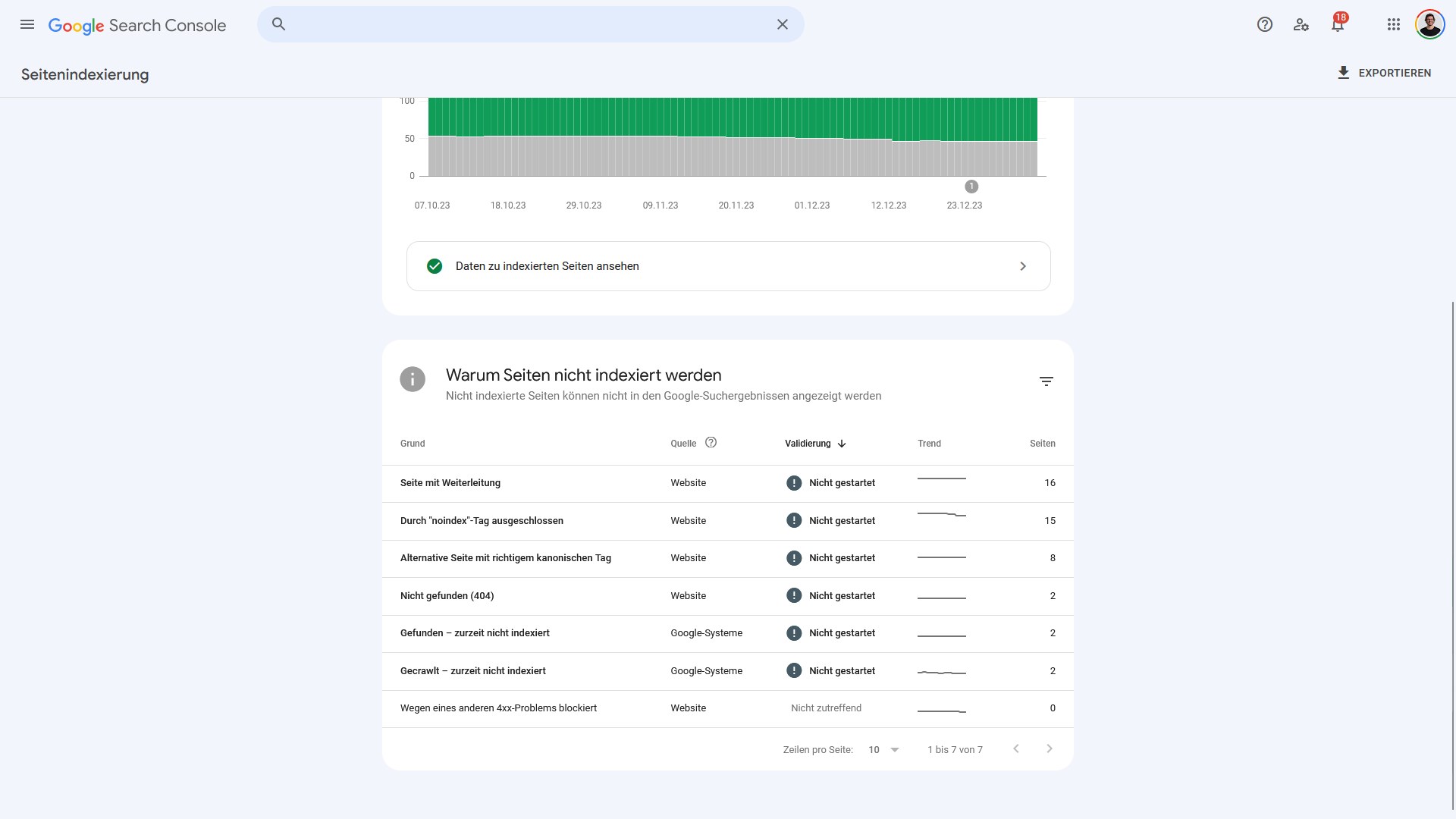
Die Frage mit Blick auf die Indexierung ist immer, ob wichtige Seiten nicht indexiert wurden und ob (viele) irrelevante Seiten von Google indexiert worden sind. Aus SEO-Sicht ist es am besten, nur Seiten indexieren zu lassen, die hochwertige Inhalte (zu nachgefragten Themen) anbieten. Im Artikel zum „guten Indexierungsstatus“ findest du dazu Impulse.
Die Gründe, warum Seiten nicht indexiert werden
Vorab der Hinweis: Nicht alle der nachfolgend genannten Gründe werden bei der von dir analysierten Seite vorliegen.
Fehlerquelle: Website
Durch Einstellungen auf der Website, z.B. eine Noindex-Angabe zur Nicht-Indexierung einzelner Seiten, oder dem Canonical-Tag, können Webmaster die Indexierung steuern. In diesem Fall findet Google auf den Adressen z.B. ein <meta name=“robots“ content=“noindex“> und kann die Seite aufgrund der Einstellung auf der Website nicht indexiert. Der Grund für die nicht-Indexierung liegt also auf der Website selbst.
Neben technischen Angaben sind es vor allem die sogenannten Statuscodes, die zu einer Nicht-Indexierung von Seiten führen. Bekannt ist besonders der Statuscode 404 – in diesem Fall meldet der Webserver, dass die aufgerufene Seite nicht vorhanden ist. Entsprechend liegt kein Inhalt vor – und Google indexiert diese Seite nicht.
Schauen wir zunächst auf die Fehler, die etwas mit dem Statuscode zu tun haben. Der HTTP-Statuscode kann z.B. mit httpstatus.io geprüft werden.
Nicht gefunden (404)
Wenn eine Seite nicht (mehr) vorhanden ist, dann erscheint in der Regel eine 404-Fehlerseite und der entsprechende HTTP-Statuscode wird gesendet.
Serverfehler (5xx)
Von einem Serverfehler wird gesprochen, wenn eine Website keinerlei Informationen über das (Nicht-)Vorhandensein einer Adresse zurückliefern kann. In diesem Fall liefert der Server einen sogenannten Statuscode im Bereich 5xx zurück. Das sind in der Regel temporäre, technische Probleme.
Wenn du die Adresse in deinem Browser aufrufst und keinerlei Seiteninhalte siehst, dann liegt vermutlich nach wie vor ein Serverfehler vor. In diesem Fall sollte der Kontakt mit einem technischen Ansprechpartner gesucht werden.
Weiterleitungsfehler
Von einer Weiterleitung wird gesprochen, wenn eine Adresse auf eine andere Adresse weiterleitet. Der Server antwortet für Weiterleitungen in der Regel mit einem Statuscode von 3xx. Während 301 eine dauerhafte Weiterleitung ist, steht 302 für eine temporäre Weiterleitung. In diesem Fall ist damit zu rechnen, dass die aktuell weiterleitende Adresse wieder zurückkommt.
Weiterleitungsfehler können sein:
- Weiterleitungsketten, also viele aufeinanderfolgende Weiterleitungen
- Weiterleitungsschleifen, also ein Verweis von Seite A auf Seite B und wieder zurück. Diese Schleifen enden in der Folge nie
- Weiterleitungen auf eine Adresse, die zu viele Zeichen verwendet. Das kann beispielsweise passieren, wenn ein Pfad sich immer wieder neu aufgrund einer falschen Weiterleitung an die Adresse anhängt
- Weiterleitung zu nicht (mehr) vorhandenen oder gänzlich leeren Seiten
Überprüfe die von diesem Fehler betroffenen Adressen mit httpstatus.io oder einem ähnlichen Tool.
Seite mit Weiterleitung
Adressen, die auf eine andere Seite weiterleiten, fallen in der Google Search Console in die Gruppe „Seite mit Weiterleitung„. Da die Seite nicht erfolgreich aufgerufen werden kann (da der Statuscode 301 oder 302 ist), kann Google die Seite nicht indexieren.
Da Weiterleitungen aktiv gesetzt werden müssen, ist diese Gruppe eher als Hinweis denn als Problem zu sehen. Überprüfe allerdings, ob du die Weiterleitung bewusst gesetzt hast, oder ob ein Fehler deinerseits vorliegt.
Wegen nicht autorisierter Anforderung (401) blockiert
Wenn erst nach erfolgreicher Anmeldung ein Inhalt sichtbar wird, sehen Nutzer ohne erfolgreich durchgeführte Autorisierung einen 401-Fehler. In diesem Fall konnte Google den Inhalt der Seite nicht abrufen.
Überprüfe, ob der Zugriff auf diese Seite bewusst hinter einem Passwortschutz liegt. Falls nicht, dann entfernen den Zugriffsschutz.
Wegen Zugriffsverbot (403) blockiert
Und noch ein weiterer Fehlercode. Wenn der Server mit dem Statuscode 403 auf eine Anfrage antwortet, dann waren die Zugangsdaten nicht korrekt.
Da sich Google nie an Seiten anmeldet, handelt es sich hier um einen „falschen“ Fehlercode. Richtig wäre, die nicht übermittelten Anmeldedaten mit dem Statuscode 401 zu beantworten.
URL wegen eines anderen 4xx-Problems blockiert
In diese Fehlergruppe werden alle weiteren Fehler einsortiert, bei denen der Server mit einem 4xx-Statuscode geantwortet hat.
Den genauen Statuscode kannst du wiederum mit einem Tool wie httpstatus.io ermitteln.
Soft 404-Fehler
Von einem Soft-404-Fehler wird gesprochen, wenn eine Seite zwar erfolgreich auf eine Anfrage antwortet (Statuscode 200), aber keinen (wirklichen) Inhalt darstellt. Sollte es diese Seite nicht geben, dann lösche sie. Denn dann ändert sich die Server-Antwort für diese Adresse auf 404 für nicht gefunden.
URL wird von der robots.txt-Datei blockiert
Über die robots.txt-Datei kann Suchmaschinen der Zugriff auf Adressen verboten werden. Entsprechend weiß die Suchmaschine nicht, ob es diese Seite gibt, und wenn ja, welcher Inhalt auf der Seite zu finden ist.
In diesem Fall musst du überprüfen, ob es sich um eine bewusste Sperrung der Seite handelt. Falls nicht, kannst du die entsprechende Disallow:-Angabe in der robots.txt entfernen und damit das Crawling der Seite erlauben.
URL als „noindex“ markiert
Durch die Angabe Noindex über meta robots oder X-robots (siehe Google Hilfe) können Seiten von der Indexierung ausgeschlossen werden.
Um zu überprüfen, ob die überprüfte Seite auf Noindex steht, kannst du im Quelltext der Seite nach „Noindex“ suchen. Alternativ können dir Browsererweiterungen wie „Robots Exclusion Checker“ helfen. Dieses Plugin und weitere werden in diesem Artikel näher beschrieben.
Durch Tool zum Entfernen von Seiten blockiert
Über das genannten Tool können Seiten aus unterschiedlichen Gründen von Dritten, beispielsweise per persönlichen Daten, oder dem Website-Verantwortlichen blockiert worden sein. Das Tool steht für Websiteverantwortliche in der Google Search Console zur Verfügung, und für Dritte unter dieser Adresse.
Wenn Adressen diesem Grund zugeordnet wurden, solltest du prüfen, wer die Entfernung beantragt hat und ob diese Adressen de-indexiert sein sollen.
Alternative Seite mit richtigem kanonischen Tag
Mit dem sogenannten Canonical-Tag können Seiten markiert werden, die denselben Inhalt unter verschiedenen Adressen bereitstellen. Ein Beispiel dafür ist die Druckversion eines Artikels unter eigener Adresse und die „richtige“ URL. Idealerweise verweist die Druckversion per Canonical auf die richtige Artikelseite.
Dieser Grund für eine „Nicht-Indexierung“ ist rein als Hinweis zu sehen, solange Adressen nicht falsch zusammengefasst wurden.
Duplikat – vom Nutzer nicht als kanonisch festgelegt
Wenn mehrere Adressen denselben Inhalt bereitstellen, aber nicht per Canonical-Tag verknüpft sind, dann tauchen sie im Bericht „Duplikat – vom Nutzer nicht als kanonisch festgelegt“ auf.
Für dich gilt hier wieder zu prüfen, ob die Seiten in deinem Sinne „kanonisiert“ wurden. Wenn nicht, solltest du selbst die kanonischen Adressen über das Canonical-Tag festlegen, oder dafür sorgen, dass jeder Inhalt nur unter einer (indexierbaren) Adresse vorliegt.
Fehlerquelle: Google-Systeme
Anders gelagert sind nicht-Indexierung durch Google. In diesem Fall war eine Seite erfolgreich aufrufbar, Google hat sich allerdings dazu entschieden, die Seite nicht zu indexieren. Entsprechend liegt der Fehler bzw. Grund für die Nicht-Indexierung in den Google-Systemen.
Die Gründe dafür werden im Artikel „Gecrawlt – zurzeit nicht indexiert“ genauer beleuchtet.
Gecrawlt – zurzeit nicht indexiert
Adressen, die unter diese Gruppe fallen, sind von Google besucht worden, aber nicht in den Index aufgenommen worden.
Rund um die Behebung „Gecrawlt, zurzeit nicht indexiert“ gibt es einen eigenen Artikel.
Gefunden – zurzeit nicht indexiert
Mit gefunden meint Google, dass die Adresse bekannt ist. Bisher wurde sie aber noch nicht besucht. Das kann zu einem späteren Zeitpunkt (noch) passieren, muss aber nicht.
Da diese Adressen im Sinne des Indexierungsprozesses auf Stufe 1 sind (Auffindbarkeit gegeben, aber noch nicht besucht), muss genauer geschaut werden, was das Problem verursacht. Dazu gibt es in diesem Artikel mehr.
Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt
Es kann vorkommen, dass Seiten zwar per Canonical-Tag miteinander verbunden wurden, Google die Seiten aber nicht als ähnlich ansieht. Da das Canonical-Tag nur als Empfehlung gewertet wird, sagt diese Fehlergruppe folglich, bei welchen Adressen Google eine andere Seite als der Nutzer als kanonisch gewertet hat.
Bei „Duplikat – Google hat eine andere Seite als der Nutzer als kanonische Seite bestimmt“ muss überprüft werden, ob Fehler bei den Canonical-Tags vorliegen. Dazu müssen die betroffenen Seiten einzeln analysiert werden, am besten über die URL Inspection API. Denn dort kann schnell herausgefunden werden, welche URL Google als die kanonische Adresse für eine Seite ansieht.
Was der Indexierungsstatus nicht kann
Der Indexierungsbericht ist für Suchmaschinenoptimierer enorm wichtig. Doch der Bericht hat ein paar Limitierungen:
- Er sagt nur „so ist es“ und liefert keine Priorisierung
- Es sind nur maximal 1.000 Beispiel-URLs pro Gruppe zu sehen
- Zur Abfrage einer einzelnen URL ist der Indexierungsstatus die falsche Wahl, dazu besser die URL-Prüfung verwenden
- Seiten (erneut) indexieren lassen
- Die Daten sind nicht tagesaktuell
Besonders die Limitierung auf maximal 1.000 Adressen ist bei großen Websites ein Problem. Durch das richtige Google Search Console Setup lassen sich zwar mehr Beispieladressen erhalten, aber in den seltensten Fällen ein Gesamtbild zur Indexierung erstellen.
Das geht mit der URL Inspection API deutlich besser. Über diese kann für bis zu 2.000 Seiten pro Tag und Search Console Property der Indexierungsstatus einzelner Seiten angefragt werden. Für einzelne Seiten steht dafür in der Google Search Console die URL-Prüfung zur Verfügung.